LEAP26
LEAP26 REDMAGIC
REDMAGIC قوائم أراجيك
قوائم أراجيك TV
TV Partner With Us
Partner With Usكيف حول ChatGPT الذكاء الاصطناعي إلى أداة فعالة في كل شئ؟


9 د
شات جي بي تي ChatGPT نموذج الذكاء الاصطناعي "مُتعدد الأغراض" الأول من نوعه، والقادر على أداء الوظيفة نفسها في مساعدة البشر على إنجاز أعمالهم في وقت قصير وبكفاءة أكبر، تُرى كيف استطاع العلماء تحويل نموذج الآلة ثنائية اللغة محدودة الاستجابة إلى قاعدة معلوماتية كُبرى تناسب جميع الاغراض؟ هذا ما سوف نُجيب عنه في مقالنا لليوم.

اقتصر الذكاء الاصطناعي على البرامج العلمية المختصة في الماضي
في السابق، وفي بداية الطريق لتعرف العلماء على ماهية الذكاء الاصطناعي وتعلم الآلة Machine learning، كان استخدام البرمجة ضمن إطار خوارزمي مُصممًا لإنجاز مهام محدودة ومتعلق بوظيفة واحدة، وذلك مثل برنامج Google AlphaFold الذي أُنشأ خصيصًا لتوقع أماكن ارتباط جزيئات البروتين ببعضها البعض، وبناء النماذج النووية والأحماض الأمينية التي تُحاكي تلك الموجودة في جينات البشر، فكانت البيانات المتواجدة في البرنامج تخص تلك الناحية العلمية فقط ومُدربة على التعامل مع بيانات الأحماض النووية.
وذلك ما جعل شركة Open AI تدرك بعد تصميمها لنموذج شات جي بي تي الأول، أنها سوف تحتاج لنموذج ذكاء اصطناعي آخر مُخصص لبرمجة الروبوتات وعلى إطلاع بعلم الروبوتكس Robotics، ولكن المبرمجين وجدوا أن ذلك غير ضروري بالمرة، وأن بقليل من التعديلات التقنية والاختبار الآلي، فإن شات جي بي تي قادر على تدريب بني جنسه من روبوتات الذكاء الاصطناعي.
كيف يُبرمج الذكاء الاصطناعي في شات جي بي تي؟
للحصول على تلك النتائج العامة من قبل بوت الذكاء الاصطناعي المُتطور، كان على العلماء تطوير الطريقة التي تُعالج بها الآلات مُدخلات البشر، وذلك ما يُطلق عليه large language models أو نماذج البيانات (اللغات) الكبيرة، وهي وحدات معالجة مركزية شبيهة بتلك الموجودة في الهواتف، ولكنها تستخدم في أجهزة الذكاء الاصطناعي لتحليل مدخلات البشر واستخراج النتائج فيما يتناسب مع المعطيات المطلوبة.
ومن ذلك استطاع المبرمجون تطوير نماذج مختلفة من البرنامج مثل GPT3 و GPT3.5 وGPT-4 وغيرها كمحاولة لتقريب النتائج أكثر إلى ما يريده المستخدم في سلسلة من الاختبارات والاستراتيجيات البرمجية في تحسين النتائج.
الوصفة السحرية لبناء بوت ذكاء اصطناعي متعدد الأغراض
يعمل الذكاء الاصطناعي أساسًا من خلال مبدأ "ملء الفراغ الآتي" إذ يدخل المستخدم طلبه أو سؤاله ويحاول البوت من خلال الكلمات المعينة التي اختارها المستخدم استخراج النتائج الأفضل في سلسلة من العمليات الحسابية والتباديل والتوافيق المبنية على علم الاحتمال.
الاحتمالية Probability
لا يوفر الذكاء الاصطناعي أجوبة صحيحة مئة بالمئة، وإنما أقرب أو أبعد إلى الصواب، فنتائجه قائمة على الاحتمال في النهاية، وعلم الاحتمال كما أنه غير متوقع ومفاجئ بطريقة خاطئة أحيانًا، فإنه كلما زادت القدرة على تحليل واستخدام أكبر قدر من الاحتمالات لاستخراج النتائج، زادت شمولية وصلابة الإجابة المُولدة من قبل الذكاء الاصطناعي.
قد يبدو لك الأمر عشوائيًا إلى حد ما، ولكن الأمر مثله مثل اكتشاف حركة الجزيئات تحت الميكروسكوب والتعرف على مجال ميكانيكا الكم، جميعها أمور عشوائية ومعقدة استطاع العلماء تطويعها في إطار علمي خلاق ومبدع.
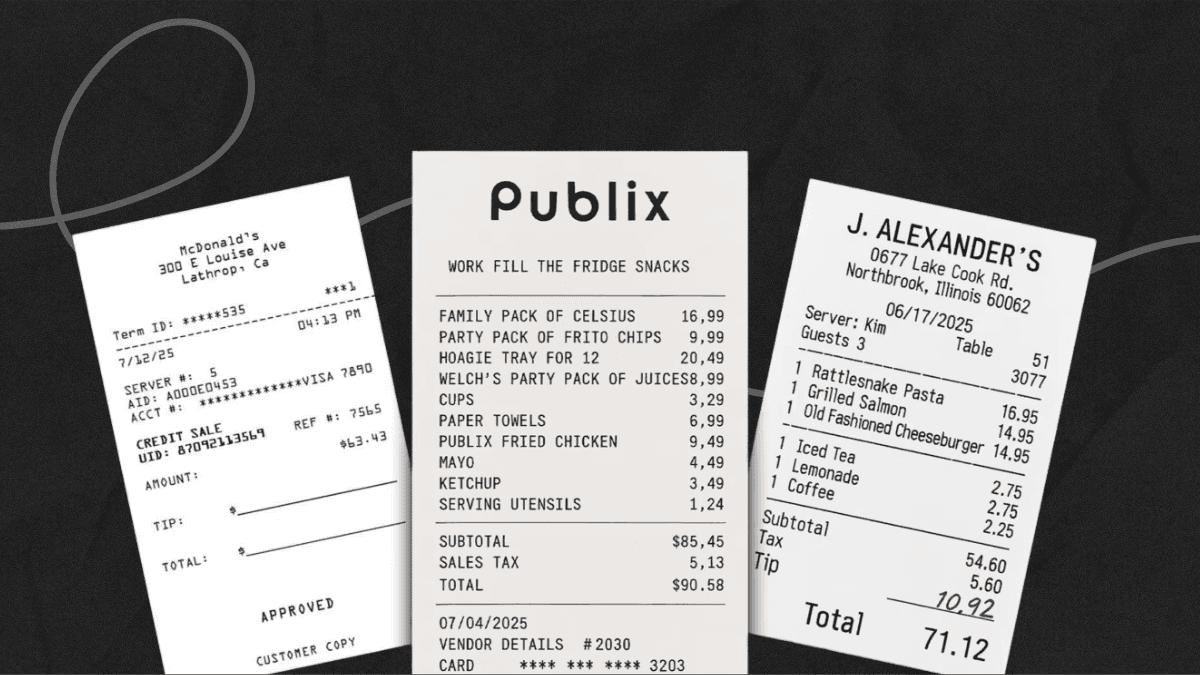
خوارزمية أصل التدرج Gradient Descent technique
يفهم الذكاء الاصطناعي لغة الأرقام المتمثلة في "كم مرة ذُكرت هذه الكلمة مع تلك" وليس كما يُكون الذكاء البشري الفطري الجُمل، فعلى سبيل المثال يفهم العقل البشري تلقائيًا أن الكتاب جماد يمكن وصفه بالجيد أو السيئ، ولا يمكن وصفه بالحزين أو السعيد، بينما يتعامل الحاسوب مع الأمر من باب الاحتمال وأن تلك الكلمة (الكتاب) -من خلال الخبرات السابقة التي تعلمها- تستعمل كثيرًا وفي تلك المواقف مع كلمتي (جيد أو سئ)، ولا تُستعمل مع كلمات مثل (حزين وسعيد).
ومن خلال ذلك الأسلوب في التحليل يستعمل العلماء خوارزمية أصل التدرج لوضع الخصائص التي يتبعها البوت في تحليل إحدى الأسئلة وتوفير الأجوبة، ويعطى البوت مجموعة من البيانات الكبيرة Big Data التي يتدرب على التعامل معها وتحليلها، وتبدو النتائج في بداية تشكيل الخوارزمية ركيكة وغير عملية، ثم تتغير المقاييس Parameters التي تعمل بها عصبونات الذكاء الاصطناعي مرارًا وتكرارًا حتى تتمكن من استخراج نتائج صحيحة وملمة بفضل مبدأ الاحتمال الذي تعمل به الآلات.
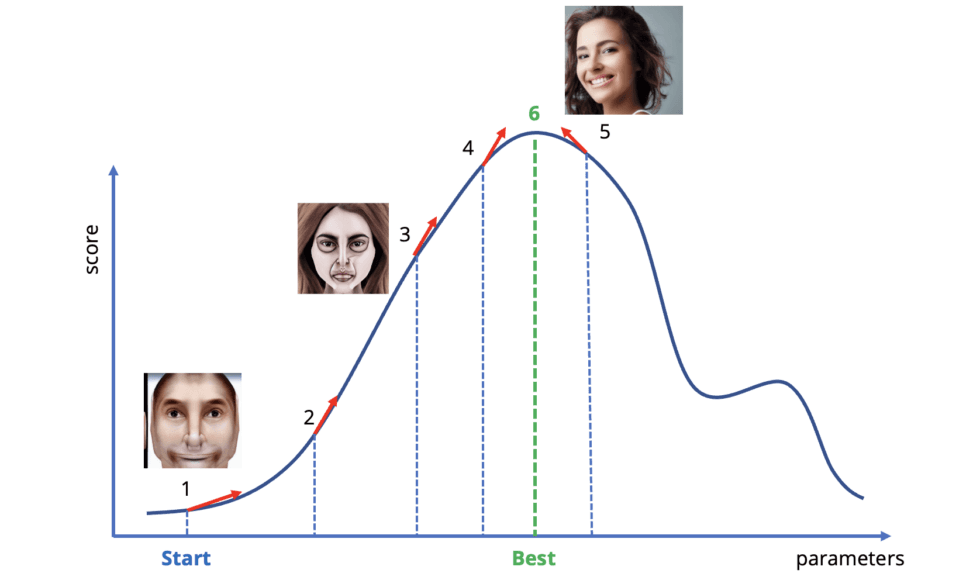
تحسين المحتوى Fine Tuning
وتعد تلك التقنية إحدى أفضل تقنيات وخصائص الذكاء الاصطناعي، وهي تعمل على استخدام خوارزمية أصل التدرج Gradient Descent، في تحويل نموذج ذكاء اصطناعي تدرب للتعامل مع مجموعة محددة من البيانات إلى أداة متخصصة في ذلك المجال، فعلى سبيل المثال توجد برامج ذكاء اصطناعي أُعدت لتحليل النصوص وتحويلها إلى صور باستخدام خاصية تحسين المحتوى، كما يُمكن تدريب هذا البرنامج لتحويل النصوص إلى شخصيات كرتونية ورسوم متحركة أكثر تعقيدًا ودقة من الصور العادية.
ولا تتوقف خاصية Fine Tuning عند ذلك الحد فقط بل إنها تعمل على تحسين استجابة الآلة بطريقة بشرية للمستخدم، وجعلها أكثر لباقة وسلاسة في الردود والمحتوى التوليدي Generative.
كيف أبدع المهندسون في تصميم ChatGPT؟
قدرة الشات المذهلة على تنفيذ الأوامر
كان النموذج الأولي الذي أُطلق من الشات هو GPT2، وكان البوت يعمل بطريقة بدائية تخرج نتائج متعلقة بالأمر ولكن غير منطقية كثيرًا، فكان الأمر أشبه بامتلاكك لفرشة واحدة كبيرة في الحجم، يمكنك رسم أشكال مبدئية من خلالها ولكنها غير قادرة على الإتيان بالتفاصيل التي تريدها في لوحتك، ثم تطور البوت بعد ذلك إلى نسخة GPT3 والتي كانت أكثر كفاءة في استخراج الأوامر المحددة والنتائج المتخصصة والأكثر تعقيدًا.
وذلك ما يسميه العلماء AI Alignment أو " Small-A Problem" وهي محاولة تطويع الآلة لجعلها أكثر قدرة على محاكاة أسلوب البشر في الكتابة والبحث عن المعلومات (التوافق مع المحتوي البشري)، أما مشكلة الذكاء الاصطناعي من نوع "Big-A" فهي الخوف من قدرة الذكاء الاصطناعي على التحكم الزائد في مجريات الحياة، وامتلاكه صلاحيات زائدة عن الحد وذلك أمر آخر قد تطرقنا إليه في مقالات سابقة.
التغذية الرجعية feedback
كل الطرق التي سبق ذكرها في المقال إلى الآن تجعل الذكاء الاصطناعي قادر علي استخراج نتائج معقولة قد تُخطئ وتُصيب في عرض ما يود المستخدم معرفته، ولكنها لا تفيد كاتب أو موسيقي أو فنان في قدرته على الإبداع، أي أنها لا توفر له محتوي جديد بخصوص ما يبحث عنه، وهنا يأتي دور التغذية الرجعية في معالجة تلك المشكلة.
لكي تحصد نتائج جديدة ومستحدثة من البوت عليك البدء من حيث انتهى الآخرون، تمامًا كما تنص القاعدة الأشهر في البحث العلمي، لذلك كان يجب تدريب الذكاء الاصطناعي على الاستفادة من المعطيات التي سبق إدخالها من قبل المستخدم، واعتبار كل نتيجة يخرجها البوت هي مجموعة من المدخلات التي سوف يستخدمها في كل إجابة تالية فيما يعرف بتاريخ البحث history research.
وذلك على نطاق الاستخدام الفردي للبوت، أما على مستوى تطور البوت ككل، فيستخدم العلماء تقنية تدعى Reinforcement Learning with Human Feedback ومن خلال تلك التقنية يتمكن الشات من محاكاة مدخلات البشر وطريقتهم في التفكير طبقًا لنماذج ومدخلات سابقة في محاولة لاستخراج نتائج أكثر مرونة بالنسبة للبشر.
أخر التطورات في تحسين الذكاء الاصطناعي
تحويل الذكاء الاصطناعي من بوت دردشة إلى وحدة معالجة متطورة
يستطيع شات جي بي تي الآن العمل كقاعدة بيانات كبرى ذات ذاكرة هائلة تقوم تسترجع إحدى المعلومات بناءً على طلبك، وذلك يعني أنها تتعامل مع بيانات قد دُربت على استخدامها من قبل بواسطة خاصية تحسين المحتوى fine tuning، ولكن لو أضفنا إلى جانب تلك القدرة الهائلة على تخزين البيانات، إمكانية التعامل مع بيانات جديدة كليًا ولم يتدرب عليها الحاسوب من قبل، ماذا لو تحول الذكاء الاصطناعي من أداة محادثة إلى أداة معالجة وبرمجة متعددة الأغراض ويمكن توصيلها بمختلف الأجهزة؟
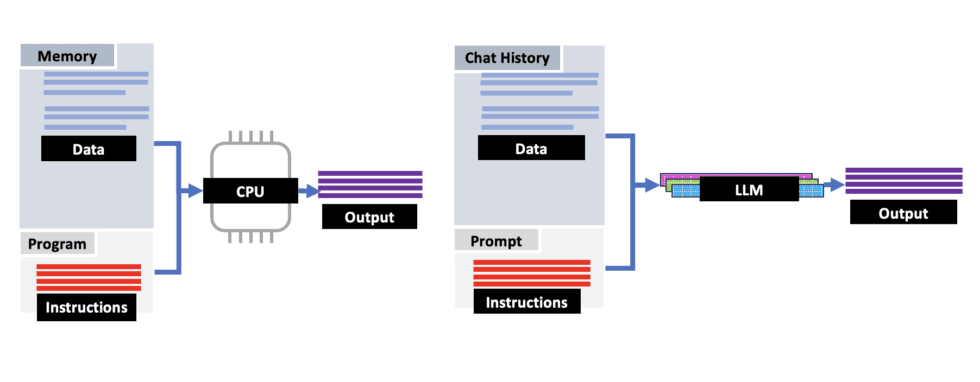
لنقرب الصورة أكثر إلى ما يطمح إليه العلماء فيما يخص الذكاء الاصطناعي في المستقبل، يمكننا الاستعانة بالقليل من الأمثلة من واقع الحياة العملية:
التعامل مع المستندات والنصوص
على سبيل المثال، لنفرض أن إحدى شركات التأمين أرادت إنشاء برنامج ذكاء اصطناعي خاص بها لمساعدة العملاء، سوف تقوم الشركة بذلك عن طريق إدخال جميع البيانات الخاصة بسياستها المُتبعة وخدمة العملاء وغير ذلك إلى الشات ثم تدريبه على استخدامها تبعًا لطرق البحث لإرشاد المستخدم، ولكن سوف تظهر مشكلتين، الأولى هي أن أي تغيير بسيط في سياسات الشركة سوف يؤدي إلى ضرورة إعادة التدريب والضبط للشات من جديد، كما أن السياسة المتبعة لخدمة عميل ما، ليست هي نفسها المثالية لخدمة عميل أخر، أي أن الخصوصية في الشات سوف تكون مخترقة.
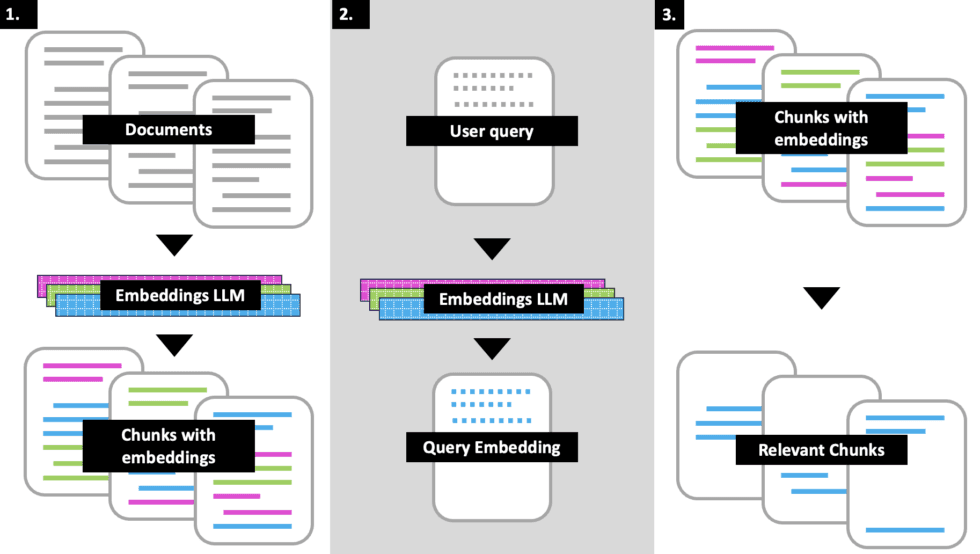
تأتي هنا فائدة تحويل الشات إلى وحدة معالجة مركزية، يمكن إدخال القواعد والسياسات العامة من خلالها، وتدريبها على الإجابة واستخراج المعلومات حسب كل طلب وحالة، وهنا يأتي دور خاصية التضمين embedding وهي عبارة عن استخدام للرموز والأرقام التي تفهمها الآلة للاستدلال على العبارات والمفاهيم Concepts التي استعملها البشر، إذ تُفلتر البيانات التي تُدخل إلى الشات، واستخراج العبارات المفيدة منها وإعطائها رموز وأرقام حسب كل مفهوم للاستدلال عليها فيما بعد ومعالجتها.
من خلال ذلك، يمكن تحويل شات الذكاء الاصطناعي إلى محرك بحث شامل التنقل والربط بسلاسة بين الرموز والمفاهيم للإجابة عن كافة أسئلتك بما يتناسب أفضل مع الكلمات التي استخدمتها، فمثلًا سوف يفهم الذكاء الاصطناعي أن كلمة "رسوم" يمكن استخدامها في الأسئلة التي تخص الدفع أو الخصم أو التكاليف الإضافية وحسب سياق السؤال سيتمكن من استخدامها في الشكل الصحيح، وبذلك سيكون أمام المستخدم نسخة إلكترونية من موظف خدمة العملاء تتيح له الاستفسار عن كافة القوانين والخدمات.
التعامل مع الروبوتات
ما توصل إليه العلم الآن من برمجة للروبوت وتحسين قدراته على الاستشعار، والحركة وتحريك الأشياء واستخدام الحواس المرئية هو أمر رائع حقًا، ولكن جميع هذه التطبيقات هي قدرات فردية من الصعب تطويعها لأداء مهام الحياة اليومية دون الحاجة إلى برمجتها باستمرار.
فإذا أردت من الروبوت أن يحل محل موظف البريد في الشركة والتقاط إحدى الطرود من مكتب في الطابق الأول إلى مكتب في الطابق الثالث ثم تحضير فنجان من القهوة وإحضاره لك بعد عودته، فسوف يتطلب ذلك منك برمجة الروبوت وإخباره بنوع الطرد، ومكانه في الطابق الأول، ومكان التسليم، ونوع القهوة، ومكان المطبخ… إلخ.
يسعى الذكاء الاصطناعي لاختصار كل تلك الأوامر البرمجية التي تحتاج إدخالها في جملة مثل "سلم الطرد إلى الطابق الثالث".
ويعمل العلماء على تحقيق ذلك من خلال استخدام لغة التضمين، ولكن تلك المرة في اختصار وترميز أوامر روتينية كتحضير القهوة وتمييز الطرود، وإيصالها إلى أماكنها، ثم تكوين نموذج مرجعي retrieval model تستطيع الآلة الرجوع إليه، إذا ما طلبت منها في المرة القادمة إيصال طرد ما إلى زميلك في العمل.
الخلاصة






باختصار يعمل العلماء الآن على فهرسة وتضمين كافة المعلومات والمفاهيم التي سوف يتمكن من خلالها الذكاء الاصطناعي من معالجة البيانات وإصدار النتائج بدلًا من تخزينها واستخراجها فيما بعد بناءً على طلب المستخدم.
يسلك الذكاء الاصطناعي في تطوره، الطريق نفسه الذي سلكته رقاقات أشباه الموصلات في تحويل أجهزة الحاسوب الضخمة إلى هواتف ذكية تُحمل بخفة في أيدي مستخدميها، مما يعني رفيقًا إلكترونيًا يمكن استخدامه أينما كنت، لذلك يمثل الذكاء الاصطناعي وتطبيقاته ثورة جديدة وفريدة في عالم التكنولوجيا الرقمي، سوف تجعلنا قادرين على تلقي المساعدة من الآلات في أي مكان وفي أي وقت.
عبَّر عن رأيك
إحرص أن يكون تعليقك موضوعيّاً ومفيداً، حافظ على سُمعتكَ الرقميَّةواحترم الكاتب والأعضاء والقُرّاء.